[개념정리] MLP(Multi Layer Perceptron)
MLP(Multi Layer Perceptron)
본 포스트는 포스코 청년 AI Big Data 아카데미 교육과정 중 AI과정에서 POSTECH 최승진교수님(BARO CTO)의 강의를 기반으로 작성했습니다.
지난번 Perceptron이 XOR문제를 해결하지 못해 AI의 암흑기가 찾아왔다고 설명했다. 하지만, 이는 Layer를 여러개 쌓는 것으로 해결할 수 있다. 아래와 같이 두 개의 선으로 XOR을 분류할 수 있다. 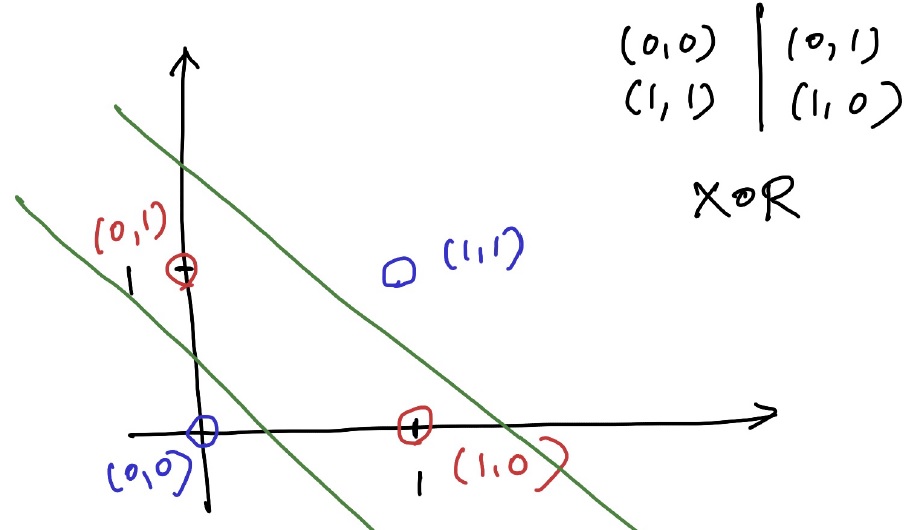
즉, 아래의 그림에서 기존의 Perceptron(왼쪽)에서 Hidden Layer를 더 쌓아서 오른쪽과 같이 진행하면 해결된다. 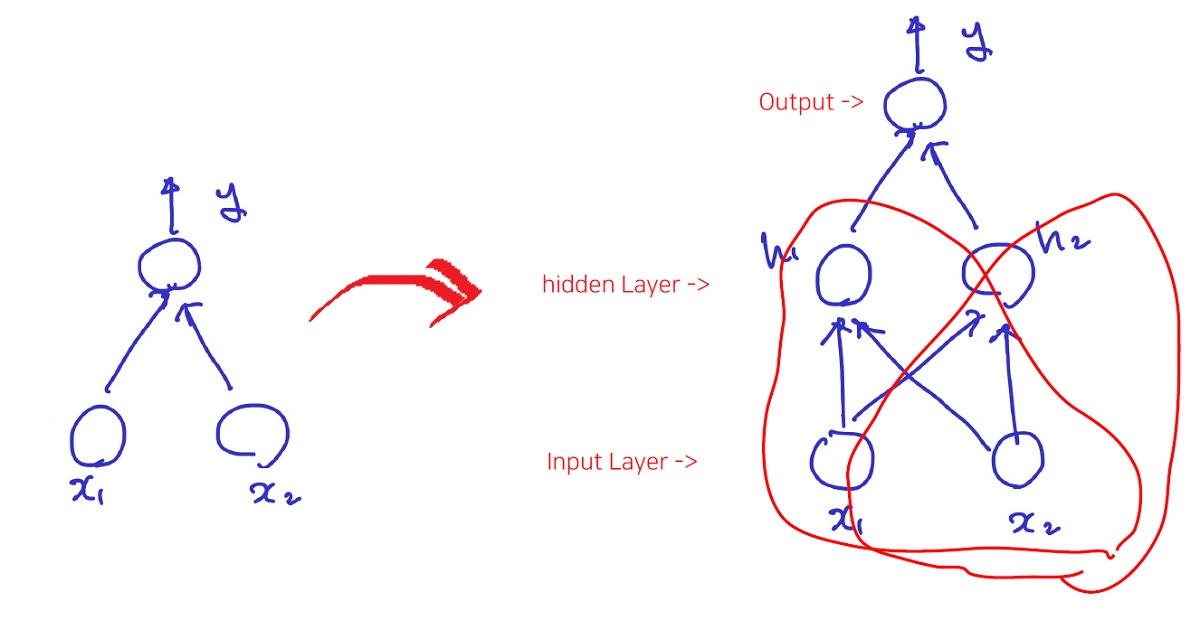
XOR 문제를 Hidden Layer를 써서 아래와 같이 풀어낼 수 있다.
출처 : 곰가드의 라이브러리 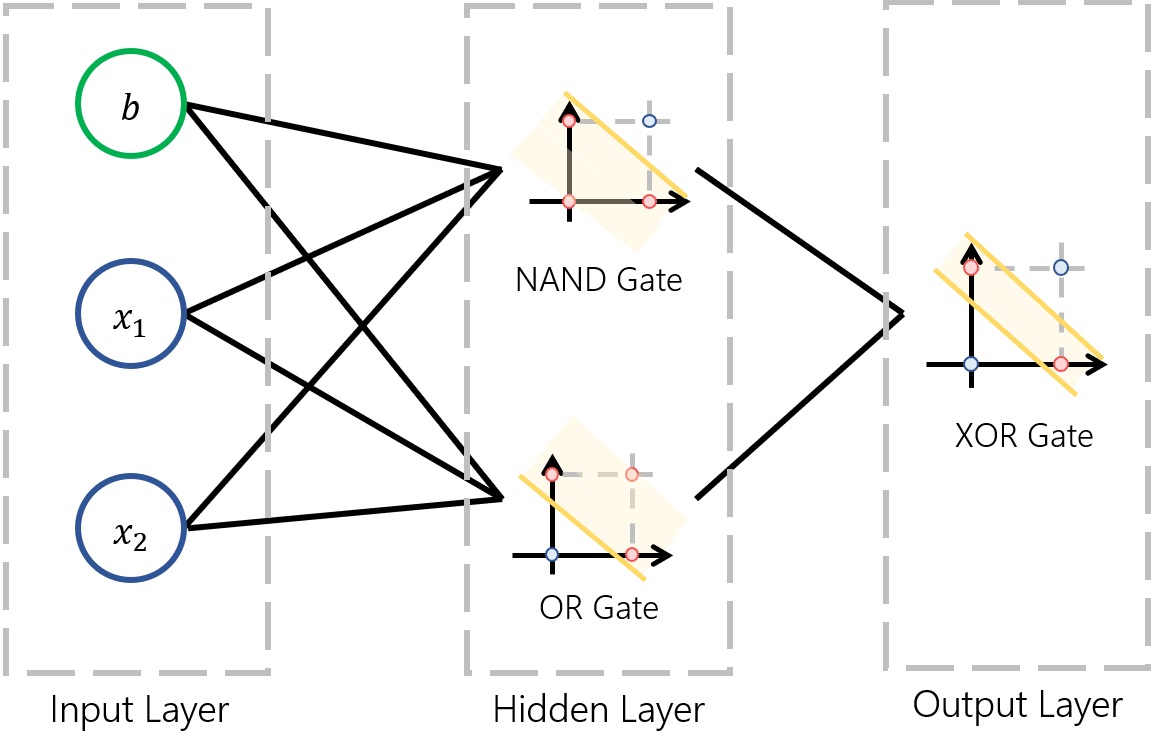
위와 같이 Hidden Layer에서 각각의 노드는 NAND와 OR을 Classification을 하고, 이것이 합쳐져 Output Layer에서 XOR 분류를 해낼 수 있게 된 것이다.
또 다른 예시를 통해 자세히 알아보자. 아래와 같은 데이터셋을 두개의 집단으로 분류한다고 하자. 이는 XOR과 같이 직선 두개로 해결할 수 없다. 올바르게 분류하기 위해선 오른쪽과 같이 4개의 직선을 이용하여 분류할 수 있다. 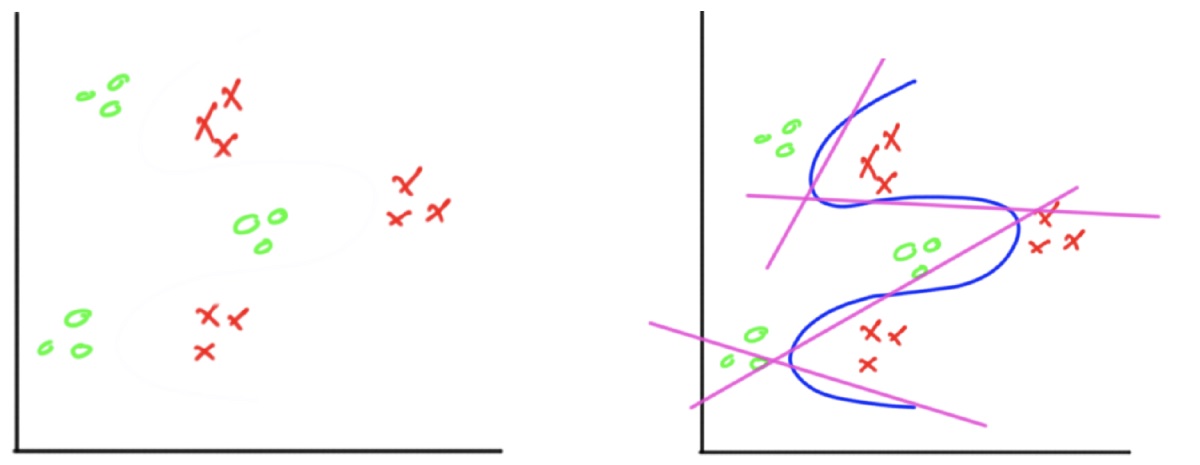
첫 번째 Hidden Layer에선 4개의 직선(노드)를 통해 분류하고, 두 번째 Hidden Layer에서 각각의 직선이 합쳐진다. 또 이 직선들이 Output Layer에서 합쳐져 데이터셋을 분류할 수 있다. 전체적인 프로세스는 아래와 같다. 
이와 같이 은닉층(Hidden Layer)가 하나 이상 존재하는 Perceptron의 형태를 MLP라고 부른다. 일반적으로 Hidden Layer가 2개 이상일 때 DNN(Deep Neural Network)라 부르고 우리가 흔히 아는 딥러닝이 DNN을 이용한 학습법이다.
우리는 Layer의 수와 Layer의 노드 수의 증가시킴에 따라 더 복잡한 문제를 풀 수 있다는 결론에 도달했다. 하지만, ‘Universal approximation theorem’ 이라는 이론이 있다. 쉽게 얘기하자면, Activation function이 비선형이고, Hidden Layer가 하나라도 존재한다면 어떠한 형태의 함수든 근사가 가능하다고 한다. 즉, 과하게 Layer수를 늘리지 않아도 다른 hyperparameter의 최적화 만으로도 효율적인 모델을 만들 수 있다. 2010년 이전에는 컴퓨팅 능력이 받쳐주지 못해서 Layer수를 줄이고 Node수를 늘리는 쪽으로 연구가 많이 진행되었다고 한다. 하지만, 2010년 이후에는 Layer수를 늘리고 Node수를 줄이는 쪽으로 많이 기울었는데, 그 이유로는 전자의 경우는 Vanishing Gradient 문제를 야기하는데, 해당 문제가 많이 해결되었고 컴퓨팅 능력또한 향상되었기 때문이라고 한다.
하지만, 개인적인 생각으론 정확도가 높으면서 간단하여 빠르게 분류가능한 모델이 좋다고 생각한다. 연구목적인 경우는 얘기가 다르겠지만 현업에서 필요한 모델은 그런 모델이 아닐까 감히 생각해본다.. 그렇기 때문에 단순히 Layer수를 늘리는 것보단 효율적인 모델을 만들 수 있도록 노력해보도록 하자.

숨만 쉬어도 돈을 벌수 있다면 얼마나 좋을까..